随着人工智能技术的快速发展,自然语言处理(NLP)领域的趋势变得愈加重要。特别是语言模型的进步,深刻改变了计算机与人类语言的互动方式。其中,Tokenim助词格式作为一种独特的语言表示方法,近年来引起了广泛关注。本文将深入探讨Tokenim助词格式的定义、特点、应用及其在NLP中的重要性。
Tokenim助词格式是一种独特的表示自然语言中助词的机制。助词在许多语言中都起着重要作用,例如汉语、日语和韩语等。在汉语中,助词常常用来表示句子的语法关系、强调或语气。例如,“了”、“着”、“的”等词就是汉语中的助词。而在Tokenim助词格式中,这些助词被视作一种独立的“令牌”或“token”。
This means that the model treats the grammatical particles as distinct elements, which allows for more nuanced understanding and generation of natural language. Tokenim助词格式采用了一种分词的策略,将助词与主要词汇分开处理,这样可以在模型训练和推理时更好地保持语言的语法结构。

Tokenim助词格式具备以下几个显著特点:
Tokenim助词格式的应用范围十分广泛,以下是一些典型的应用场景:
机器翻译系统需要精确理解源语言的语法结构,以生成流畅的目标语言文本。Tokenim助词格式通过将助词单独处理,帮助模型更准确理解句子含义,从而提高翻译的质量。
在文本生成任务中,模型需要生成符合语法的句子。Tokenim助词格式能够减少语法错误的发生,并使生成的文本更加自然和符合人类的表达习惯。
情感分析任务需要理解用户情感的语境,助词往往会对情感的表达起到很大的作用。利用Tokenim助词格式,情感分析模型可以更好地捕捉文本的情感基调。
在语音识别系统中,通过Tokenim助词格式处理助词,可以有效提高识别的准确性,尤其是在复杂对话环境中,理解助词的作用显得尤为重要。
在信息检索系统中,助词的使用频繁影响到关键词的抓取和理解。Tokenim助词格式通过对助词的独立处理,有助于改进搜索的相关性和准确性。
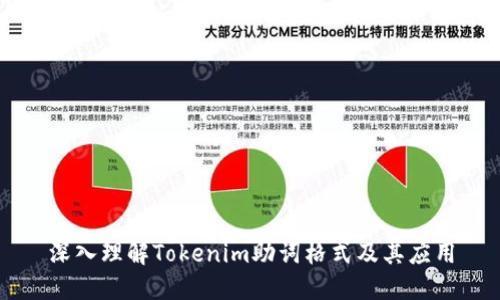
传统的助词处理往往将助词视为句子的一部分,与其他词汇一起进行解析和处理。这样的方式可能在处理复杂的句子时导致模型的理解出现偏差。而Tokenim助词格式则将助词单独处理,使其成为独立的token,这样可以清晰地捕捉助词在句子中的作用和位置,减少了因语法混淆而产生的错误。
面对多语言处理的挑战,Tokenim助词格式展现出较强的灵活性和适应力。许多语言的助词功能各不相同,Tokenim助词格式通过独立解析助词,可以更好适应这些语言的特性,从而提高语言转换或翻译的准确性。这种协同性极大增强了模型在全球范围内的适用性。
在实施Tokenim助词格式时,有几个方面需要格外注意:首先,要确保助词的定义准确,避免漏掉重要助词;其次,训练数据的质量非常关键,好的数据集可以使模型在捕捉助词的细微变化时表现得更优秀;最后,模型的设计也要相应调整,以支持助词的独立处理,确保整体架构兼容这一格式。
Tokenim助词格式未来的发展方向主要集中在几个方面:第一,扩展更多语言的支持,尤其是一些少数语言也希望能纳入到该分析机制中;第二,结合其它先进技术,如深度学习和迁移学习,进一步提高性能;第三,研究者也将探索如何将该方法与新的NLP任务结合,如对话生成、文本总结等,以开拓更多的应用领域。
评估Tokenim助词格式的效果可以通过几个标准来进行:首先,比较使用与不使用Tokenim格式的模型在特定任务(如翻译、生成)的准确率和流畅度;其次,可以通过用户反馈来评估文本的自然程度;最后,进行深入的错误分析,了解Tokenim助词格式能在多大程度上减少模型常见的语法错误和语义歧义。
在全面了解Tokenim助词格式后,可以看出其在自然语言处理领域中的重要性,不仅提高了模型的解释能力,也使得应用更加广泛。随着技术的进一步发展,Tokenim助词格式有望在未来的AI应用中发挥更大的作用。




leave a reply